今年もアドベンドカレンダー「ほぼ横浜の民 Advent Calendar 2022」を書く.
MLOpsについて自分が勉強した備忘録を記す.
この記事 (勉強編) ではMLOpsをBig Tech各社の説明や実例, 幾人のエキスパートの発表などから探る.
主にその定義や成熟度合いの基準, 必要となる要素や技術についてまとめる.
今後ではあるが, (実装編) でMLOpsに関わるいくつかの有名なサービスやライブラリを実際に使い, 簡単な機械学習サービスを立ち上げる試行錯誤の様子を公開予定だ.
動機
私は普段AIのモデルやシステムはその場・その時のモノを作成しがちだ.
パイプラインの設計に決まりは特になく, 何かしらの課題に対し手頃なデータを用意し, モデルを見繕い, こちらに責務があればデプロイし, てきとうに用意したScriptで評価や効果を可視化し, それらしい資料を添え, 今回の施策を説明して終わりというお決まり (行き当たりばったり) の流れで生きている.
小規模な開発や継続的なモデルの運用や改善をしない場であればこのやり方でも間に合っているが, これで良いのかと思うことが最近増えた.
また, 世の中のデファクトスタンダードな機械学習開発とは何だろうかと思い, MLOpsを学んでみようと思った次第だ.
MLOpsとは
MLOpsとは「機械学習モデルの効率的な実装やデプロイ, 運用することを目的とした一連のプラクティスおよびその概念」であるそうだ.
機械学習 (Machine Learning) と運用 (Operations) を組み合わせた造語であり, 定義は色々と見られる.
どうやら一般のソフトウェア開発にはないML開発特有の課題 (Hidden Technical Debt in Machine Learning Systems) を解決するためのものだそうだ.
まずはBig Tech各社 = Microsoft, Google, AWS の説明を簡単にさらいMLOpsとは具体的に何かを探る.
Microsoftの説明
Microsoft (MLOps: Model management, deployment, and monitoring with Azure Machine Learning) では,
MLOpsはワークフローの効率を高める継続的なインテグレーション, デリバリ, デプロイなどDevOpsの原則と実践に基づいていると定義している.
これらをMLプロセスに適用する目的は以下であると述べている.
- ・モデルのより迅速な実験と開発
- ・実稼働環境への迅速なモデルのデプロイ
- ・品質保証
また, MLOpsのDevOpsと比較した特性の違いを以下のように述べている.
- ・開発と運用に先立って探索を行う.
- ・データサイエンスのライフサイクルに適応性のある作業方法が求められる.
- ・データの品質による制限や可用性による制限が進行する.
- ・DevOpsより大きな運用作業が必要になる.
- ・作業チームにはスペシャリストとドメインエキスパートが必要になる.

これを説明するMLOpsの原則として以下を挙げている.
-
・コード, データ, 実験の出力にバージョンを適用
従来のソフトウェア開発とは異なりデータはモデルの品質に直接影響するため実験や推論の結果を再現できるよう実験コードのバージョン管理に加え, データセットのバージョン管理を行う必要がある. -
・複数の環境の使用
開発とテストを運用作業から分離するため少なくとも2つの環境にインフラストラクチャをレプリケートする必要があり, ユーザーのアクセス制御は環境ごとに異なる場合がある. -
・インフラストラクチャの管理
作業環境でインフラストラクチャコンポーネントを作成および更新する場合は環境内で不整合がないように注意する.
複数の環境で実験のバージョンを簡単に再実行, 再利用したりできるように実験のジョブの仕様構成をコードとして管理する. -
・ML実験のトレーサビリティを管理
ML実験に関する評価指標やその他の成果物のトレーサビリティを確保する.
ジョブのパフォーマンスの履歴を残し定量的に解析し, チームの協業と機敏性を改善する. -
・コードテスト, 整合性検証によるモデルの品質確認
特徴抽出, データ整合性, モデルのパフォーマンスについて実験コードベースをテストする. -
・継続的インテグレーションとデリバリ
チームでのテスト実行を自動化する.
継続的な学習パイプラインの一部にモデルの学習を含め, リリースの一部にA/Bテストを入れて定性的なモデルだけが運用環境で使用されるようにする. -
・サービス, モデル, データのモニタ
サービスをモニタしインフラストラクチャのアップタイム, コンプライアンス, モデルの品質を確認することが重要である.
データとモデルのドリフトを特定し, 再学習が必要かどうかを把握し, 自動トリガーを設定することを検討する.
MicrosoftはMLOpsに対しどの程度成熟しているかを判断するためのフレームワークである成熟度を以下のレベルで定義している.
-
MLOpsなし
チームのコミュニケーションはほとんどなく, モデルは手動で作成されトレーサビリティがない, かつエンジニアの依存性が高い.
リリースも手動であり, バージョン管理がない.
データサイエンティスト, データエンジニアのみが存在する. -
DevOpsあり, MLOpsなし
レベル0と比較し, データはパイプラインにより自動で収集され, ソフトウェアエンジニアが登場しモデルを受け取る.
モデルの統合テストがあり, リリースも自動化されている. -
学習の自動化
レベル1と比較し, データサイエンティスト, データエンジニア間のコミュニケーションが密に行われ, 学習コードやモデルのバージョン管理がされる.
MLOpsにおける学習が自動化されている. -
モデルデプロイの自動化
レベル2と比較し, モデルの統合部分に関してユニットテストや統合テストも含めたCI (Continuous Integration 継続的インテグレーション) / CD (Continuous Delivery 継続的デリバリ) が整備され, モデルデプロイの自動化がされている.
リリースまでも継続的にパイプラインで管理され, 自動で行われる. -
MLOpsの再学習完全自動化
レベル3と比較し, データサイエンティストとソフトウェアエンジニアが密に連携し, 実験コードが再現可能な状態になる.
また, データエンジニアとソフトウェアエンジニアも連携しデプロイ後のメトリック収集が実装される.
モデルの作成においてメトリック運用に基づいて再学習を自動トリガーするようになる.
さらに, MicrosoftではMLOpsを利用した開発のスケーリングについても述べている.
あるユースケースでうまくいった開発があり, それをスケーリングし他の大量のユースケースへ適用したいと考えた際, 再現可能なビジネスプロセスと標準化されたシステムであるAI Factoryが役立つ.
チームの立ち上げや推奨されるプラクティス, MLOpsの戦略や構成, ビジネス要件に合わせた再利用可能なテンプレートを最適化する.
以下はAI Factoryの主要な要素をまとめたものだ.

これらを考慮しAI Factoryの再現性を利用することで, スケーリングにおいて以下の利点が得られる.
- ・設計フェーズの高速化
- ・プロジェクト間でツールを再利用する際の他チームからの承認の迅速化
- ・コードやプロジェクトのテンプレートとして再利用可能なインフラストラクチャによる開発の高速化
Microsoftでは学習やデプロイの自動化など学習パイプラインがフォーカスされ, またそこに関わる人のコミュニケーションについても言及されている.
成熟度については4つのレベルで細かく定義されているが, 具体的なアーキテクチャの説明などは少ない印象だ.
Googleの説明
Google (MLOps: Continuous delivery and automation pipelines in machine learning) の説明を見てみると, DevOpsが大規模なソフトウェアシステムの開発と運用における一般的な手法であることに対し, MLOpsが以下の点で異なることを指摘している.
-
開発:
MLには実験的性質があり様々な機能, アルゴリズム, モデリング, パラメータを試し最適な方法を見つける必要がある. -
テスト:
MLのテストは一般的な単体テストと統合テストに加え, データ検証やモデルの品質評価が必要である. -
デプロイ:
MLシステムではデプロイモデルを自動的に再学習する必要がある. -
本番環境:
MLモデルは絶えず変化するデータやプロファイルのためにパフォーマンスが変わる可能性があり, そのためデータの統計のトレーサビリティを保ち, モデルをモニタリングすることで想定と異なる場合に通知またはロールバックする必要がある.
MLシステムと聞くとコードを書き, モデルを実装する部分に注目してしまうが, 実際の運用システムの要素としてはごく一部であり他は自動化, データ収集, データ検証, テストとデバッグ, リソース管理, モデル解析, プロセス管理とメタデータ管理, モニタリングなどから構成される.

また, GoogleではMLOpsの成熟具合について以下のレベルで定義している.
-
手動プロセス
開発者がデータの収集からモデルの構築, デプロイまで全てのステップを手動で制御する.
これはノートブック等で作成された実験的なコードによって実行され, 学習済みのモデルのみが本番サービスとしてデプロイされる.
-
MLパイプラインの自動化
MLパイプラインが自動化され, 新しいデータを使用した本番環境でモデルを再学習するプロセスが自動化されている.
Feature storeやMeta data storeが追加され, 特定のTriggerに応じ学習パイプラインが実行されサービスにデプロイする流れができている.
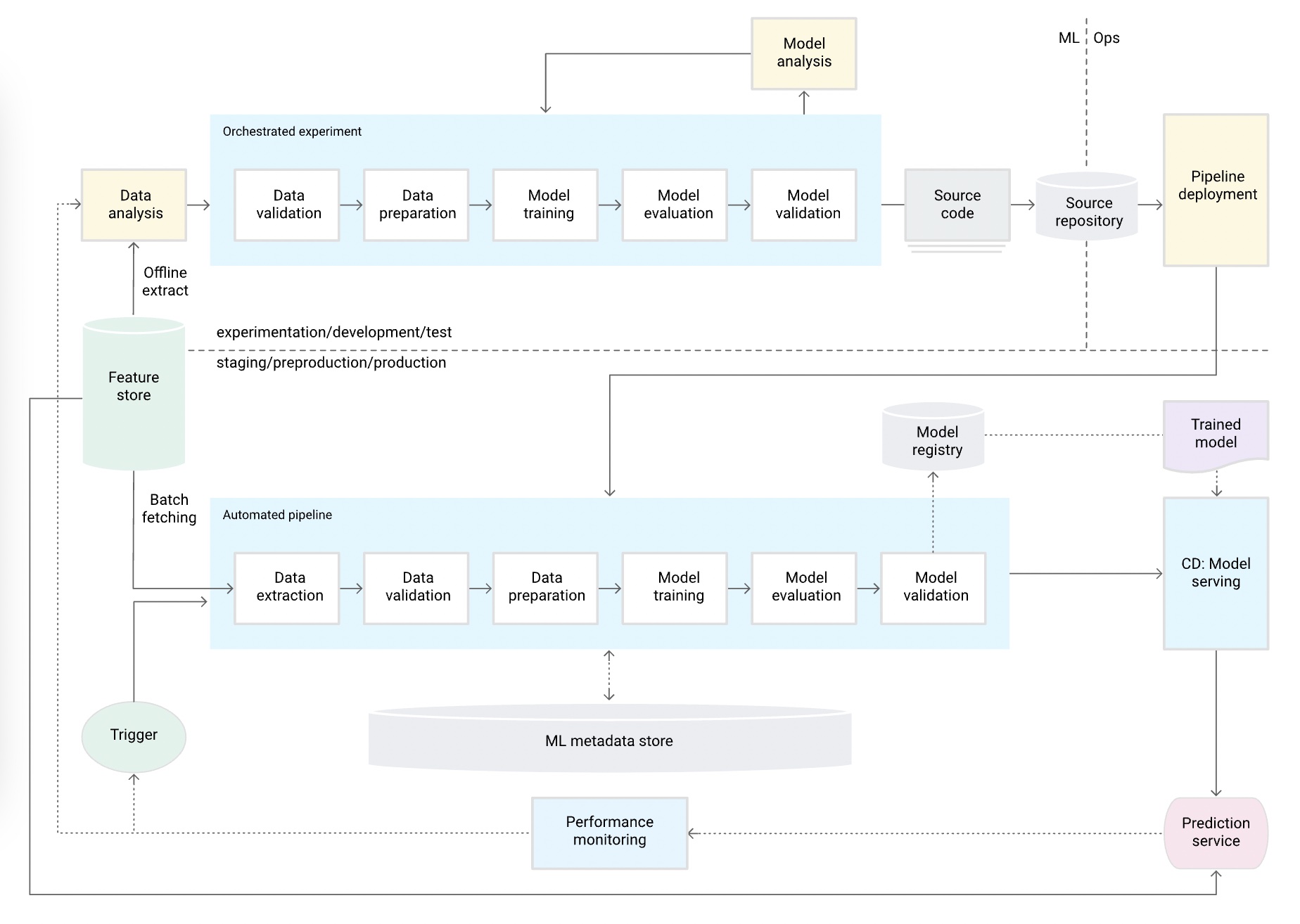
-
CI/CDパイプラインの自動化
CIパイプラインがMLパイプラインと共に自動化される.
レベル1ではパイプライン自体のデプロイが自動化しておらず複数のパイプラインの管理コストなどが課題である.
一方, 自動化されたCI/CDを使用するとSource Repositoryへの更新をトリガーに各ステージでプロセスが走り本番環境にデプロイされる.
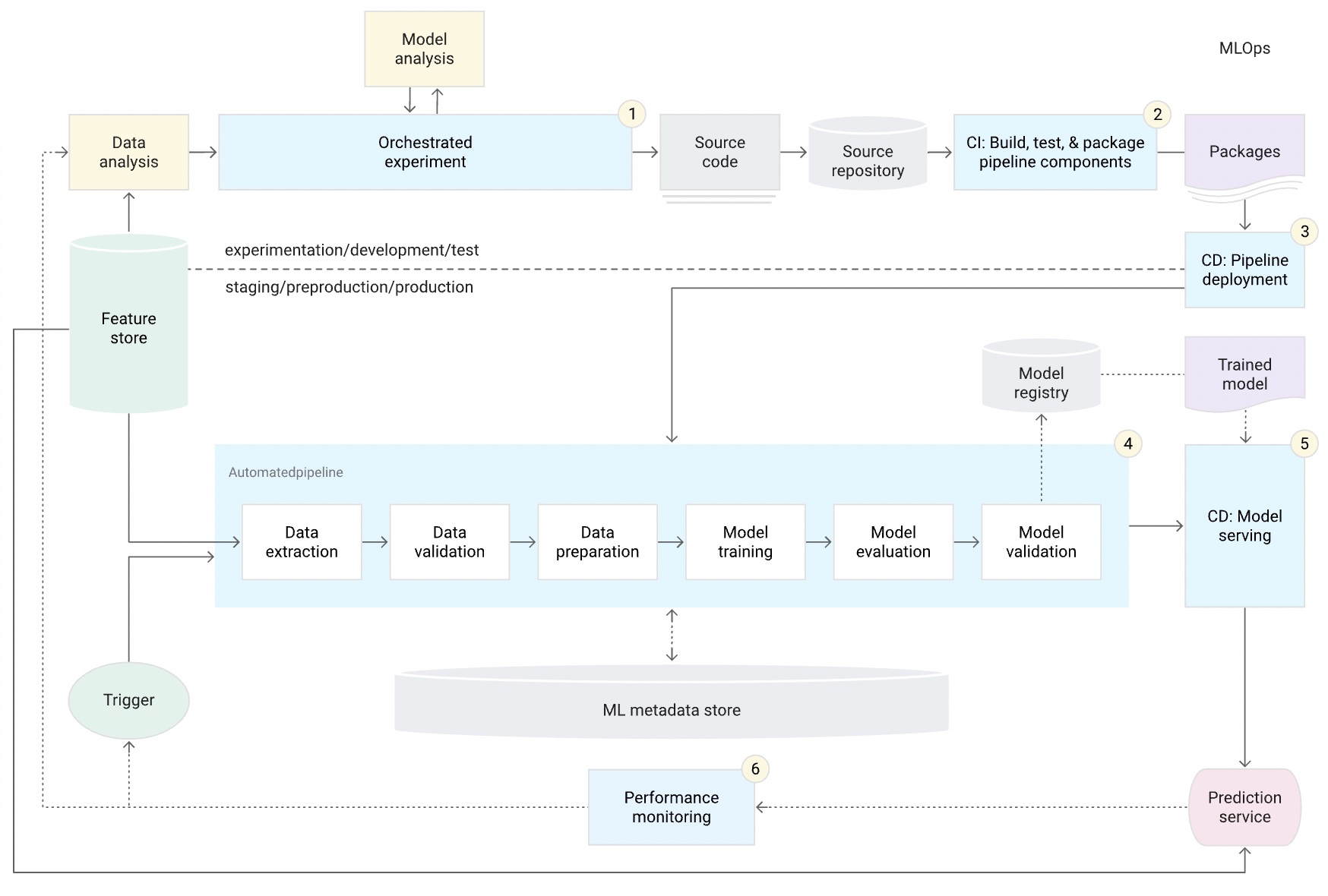
Googleでは学習パイプラインがフォーカスされているが, 人やコミュニケーションの説明はない.
成熟度についてはアーキテクチャなども触れられているが, 3つのレベルでざっくり定義されている印象である (0~1の差が非常に大きい).
AWSの説明
AWS (MLOps foundation roadmap for enterprises with Amazon SageMaker) では,
MLOpsは機械学習ワークロードにDevOpsを適用することで構築された方法論を指すとしている.
データサイエンス, データエンジニアリングを既存のDevOpsのプラクティスと組み合わせることで機械学習開発ライフサイクルを合理化する.
DevOpsがソフトウェア開発と運用を統合するのと同様にMLOpsではソフトウェア開発, 運用, セキュリティ, データエンジニアリング, データサイエンスの統合が必要である.
AWSでは, 具体的にどのサービスをMLOpsへ適用するかなどについても紹介されている.
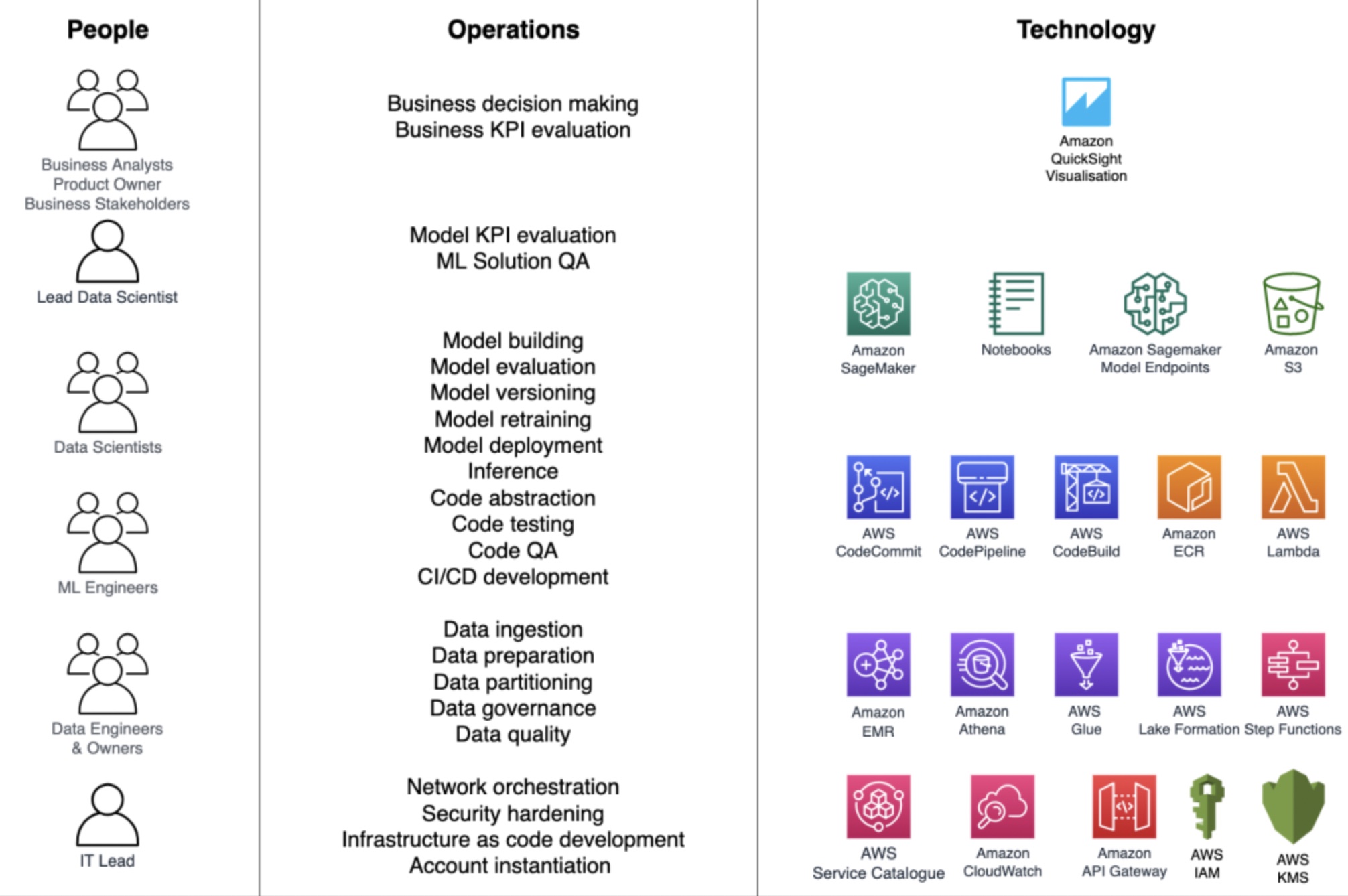
また, 企業はデータサイエンティスト, データエンジニア, MLエンジニア, ITやビジネス関係者などの複数のペルソナがどのように協業すべきかについても説明がされている.
ロールの主な役割や役立つAWSサービスを簡単にまとめた.
- 「ITアドミニストレータ」
標準的なMLOps環境を構築しユーザとデータにアクセスを提供する.- ・Model Registry
- ・CodeCommit
- ・CodeBuild
- ・Service Catalog
- 「ビジネスステークホルダ」
ビジネスに必要な意思決定をするためにデータや推論結果にアクセスする.- ・Glue
- ・Lake Formation
- ・Step Functions
- ・Landing Data
- ・QuickSight Visuallisation
- 「データエンジニア」
データを取り込みETLパイプラインを作成する.
MLユースケースに必要なデータを準備する.- ・Glue
- ・Lake Formation
- ・Step Functions
- ・Landing Data
- ・QuickSight Visuallisation
- 「リードサイエンティスト」
コードリポジトリとCI/CDパイプラインを用意する.
データサイエンティストとMLエンジニアがMLユースケースを製品化できるようにする.- ・Model Registry
- ・CodeCommit
- ・CodePipeline
- ・CodeBuild
- ・ECR
- 「リードサイエンティスト, ビジネスアナリスト, プロダクトオーナ」
デプロイされるモデルをレビューし承認する.- ・Model Registry
- ・CodeCommit
- ・CodePipeline
- ・CodeBuild
- ・ECR
- 「(リード)データサイエンティスト」
全てのモデルを評価し最も良いモデルを選ぶ.- ・SageMaker
- ・SageMaker Model Endpoints
- ・ML Data
- 「MLエンジニアまたはデータサイエンティスト」
CI/CDパイプラインを使いMLソリューションを実装するためコードリポジトリへのアクセスが必要となる.
モデルのビルドとMLパイプラインをモニタしデバッグする.- ・SageMaker
- ・SageMaker Model Endpoints
- ・ML Data
- 「データサイエンティスト」
最終的なフルスケールのモデルを作成するためMLパイプライン上でプロダクションのデータにアクセスする.- ・SageMaker Model Endpoints
- ・ML Data
AWSではMLOpsの成熟度について以下のように説明している.
Initial, Repeatable, Riliable, Scalableの4つのフェーズ (レベルという表現ではない) がある.
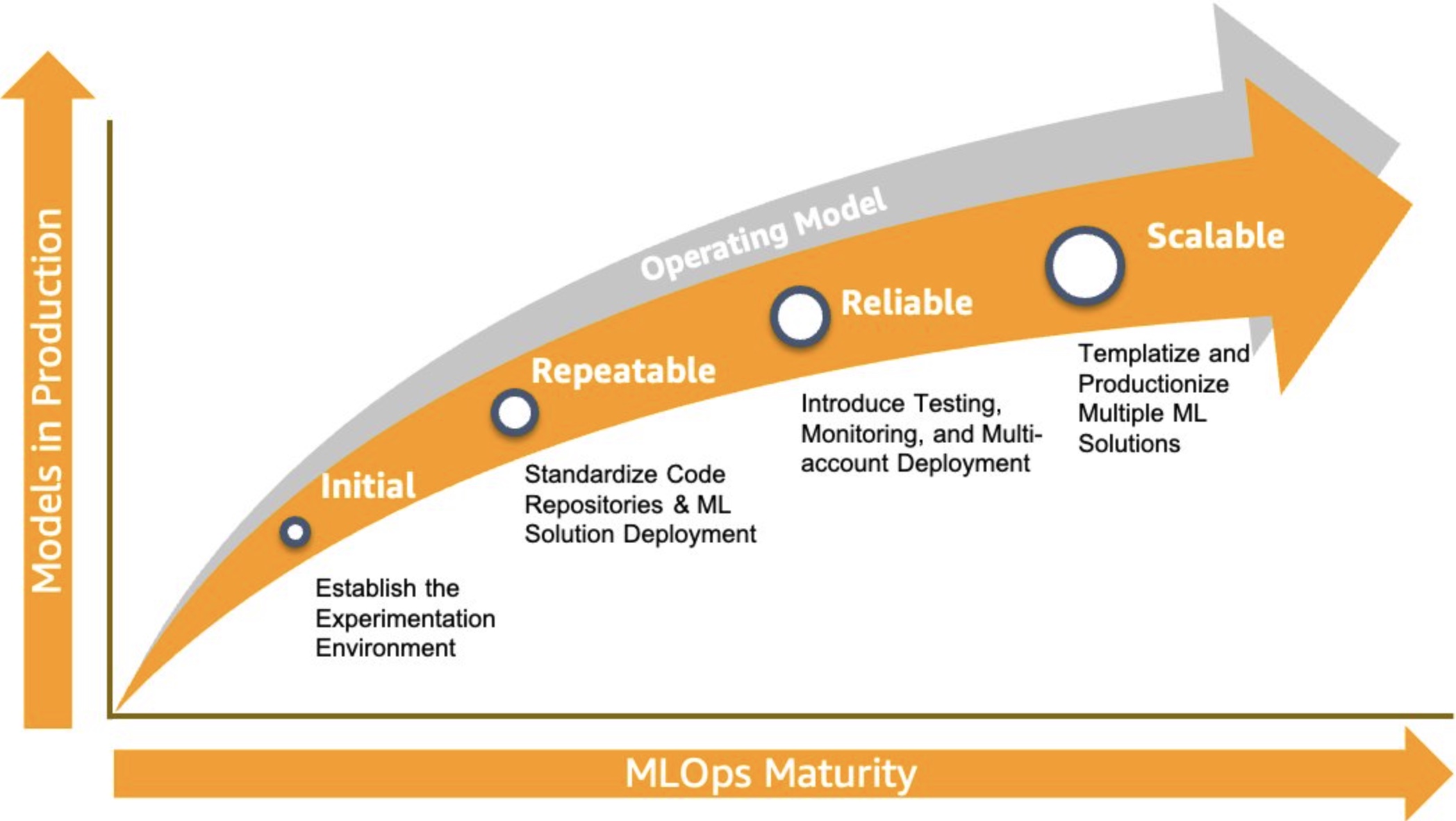
-
Initial
データサイエンティストがノートブックを使用して実験を行い, MLで特定のビジネス上の問題を解決できる安全な実験環境を作成できている.
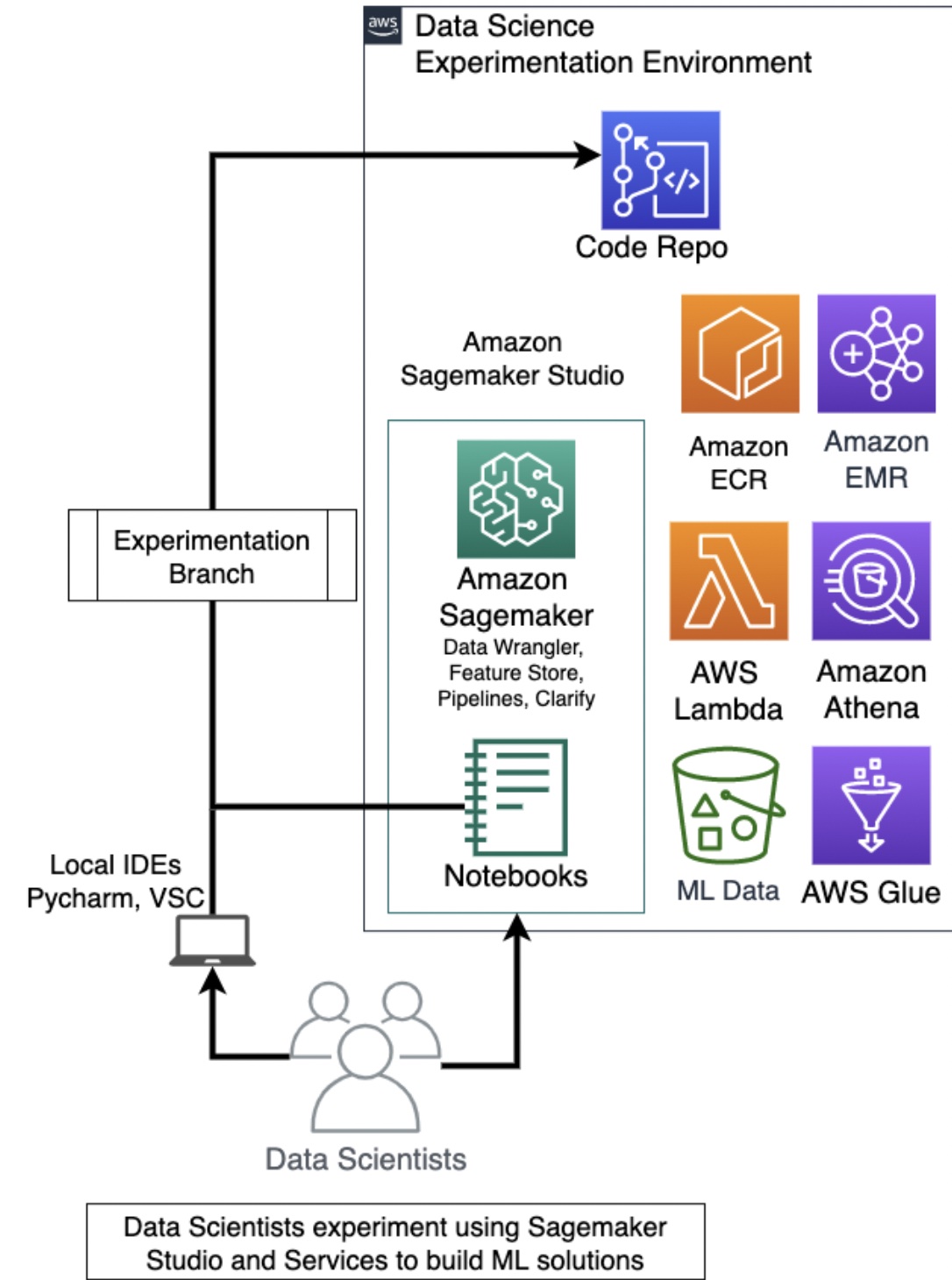
-
Repeatable
Initialフェーズから移行し, MLによってビジネス課題を解決できることを証明できた後 (PoC完了後) のフェーズである.
MLパイプラインへの移行, リポジトリのブランチのマネジメントやCI/CD等の標準化なども行われる.
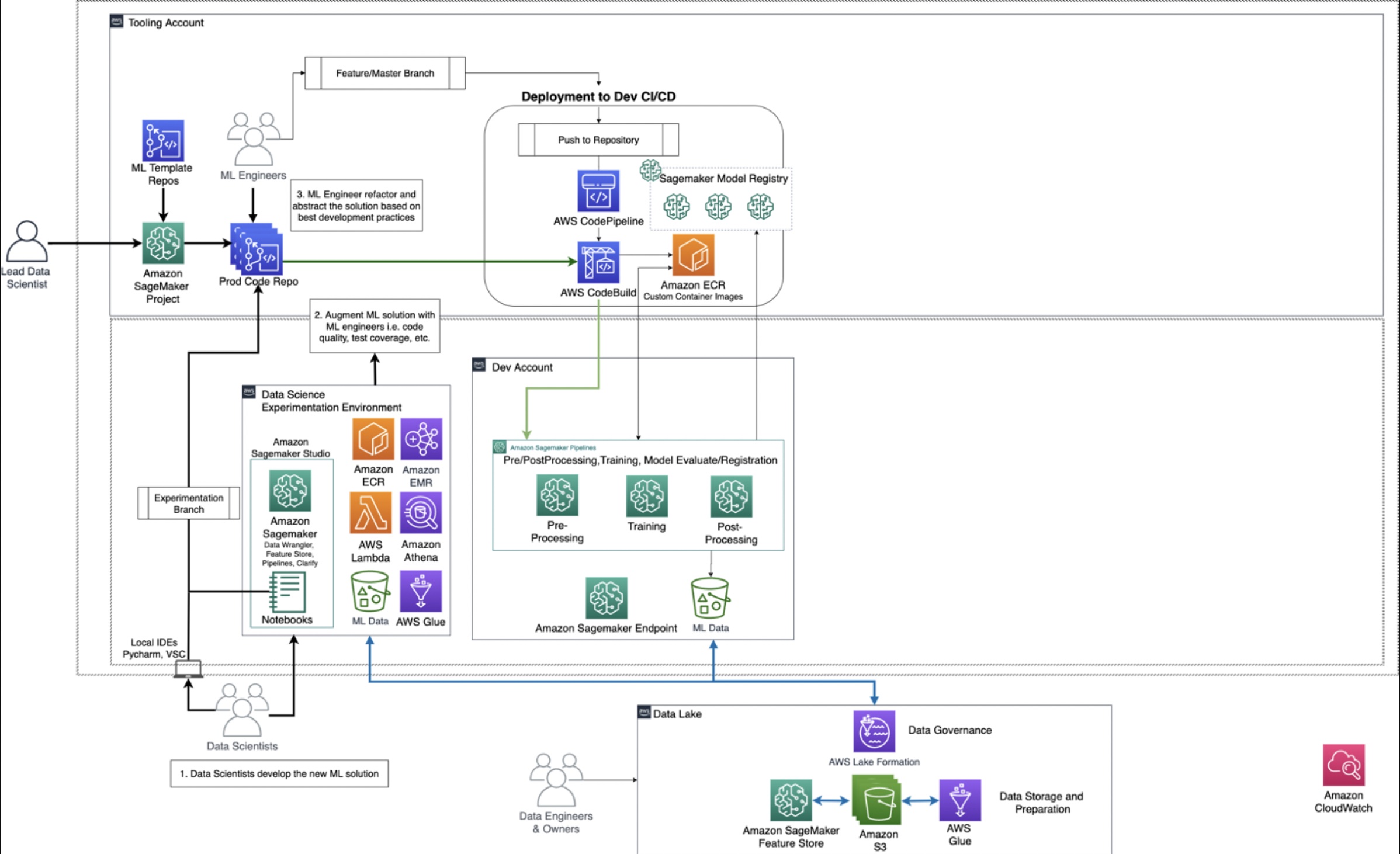

-
Riliable
このフェーズはCI/CDを通してモデルをデプロイする.
複数のペルソナが協業することで検証, 承認, デプロイのパイプラインが実施される.

-
Scalable
最初のMLユースケース製品化のための開発が完了し, 次のユースケースを見出すフェーズである.
リードデータサイエンティストが新しいプロジェクトをインスタンス化し, 新たなMLユースケースごとに専任チームを割り当てる.
複数の製品所有者がモデルの学習や展開, 実行に対し個別に請求を支払うケースではチームごとに個別のMLOpsアカウントを用意する.
新しいアカウントを簡単に作成できるよう必要に応じてアカウントをカタログ化, インスタンス化, または廃止できるようにする.
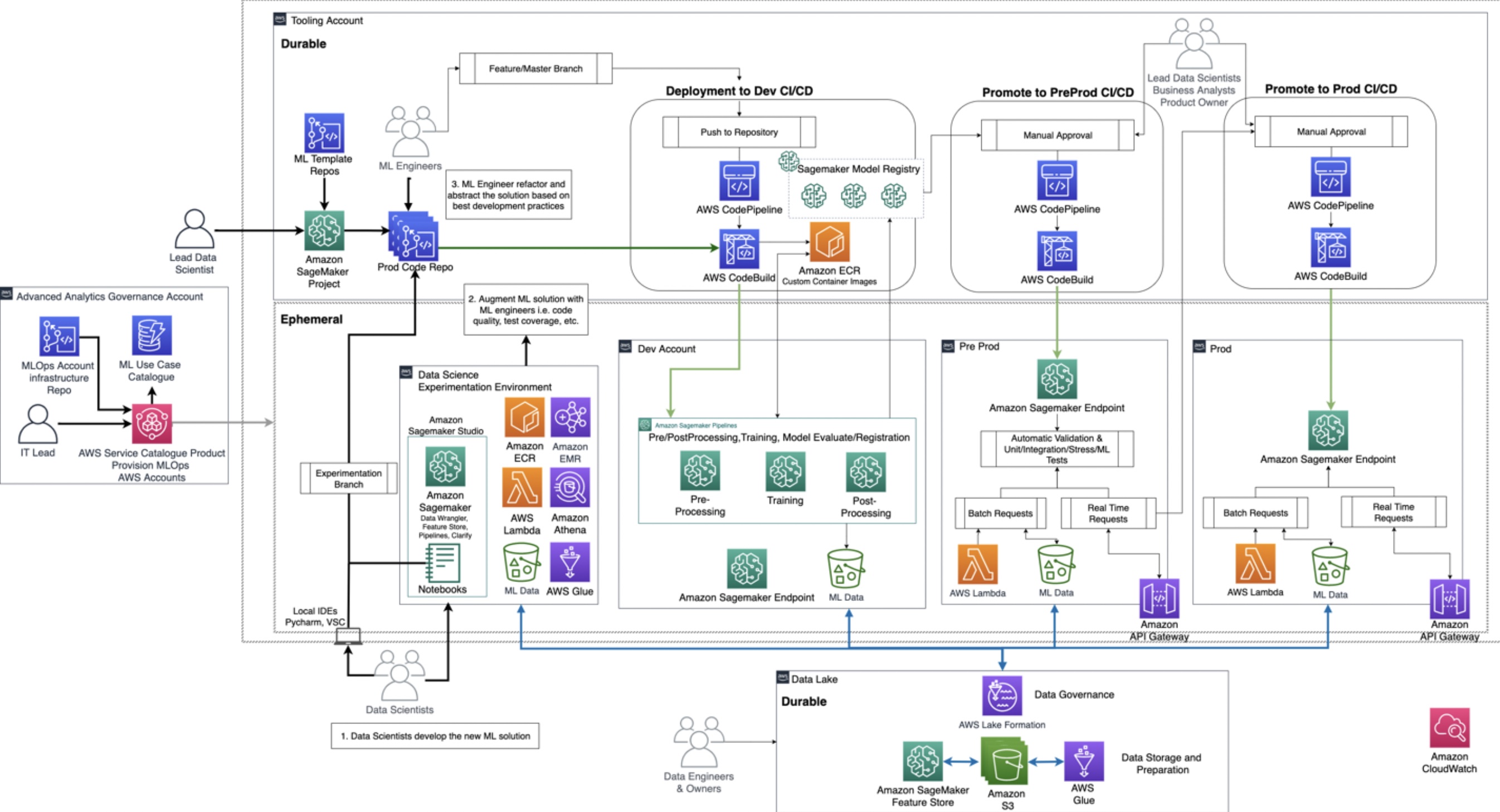
AWSでは学習パイプラインのみならずセキュリティなども言及され, MLOpsに関わる人のロールついても説明がある.
成熟度は4つのフェーズでAWSの具体的なサービスを使ったアーキテクチャを見せつつ各ロールが行う一連の作業, やりとりが細かく説明がされている印象だ.
Big Tech3社の説明まとめ
今回紹介した各社の記事では, 合理化の対象やそのレベル感は差がある印象を持ったが, まとめると以下のように説明できる.
MLOpsというのはDevOpsの延長であり, ML開発におけるデータ収集, データ検証, テストとデバッグ, リソース管理, モデル解析, プロセス管理とメタデータ管理, モニタリングといった複雑な開発サイクルを合理化することを目指している.
ツールやシステムの観点のみならずそれに関わる人のロールやコミュニケーションも重要な要素となる.
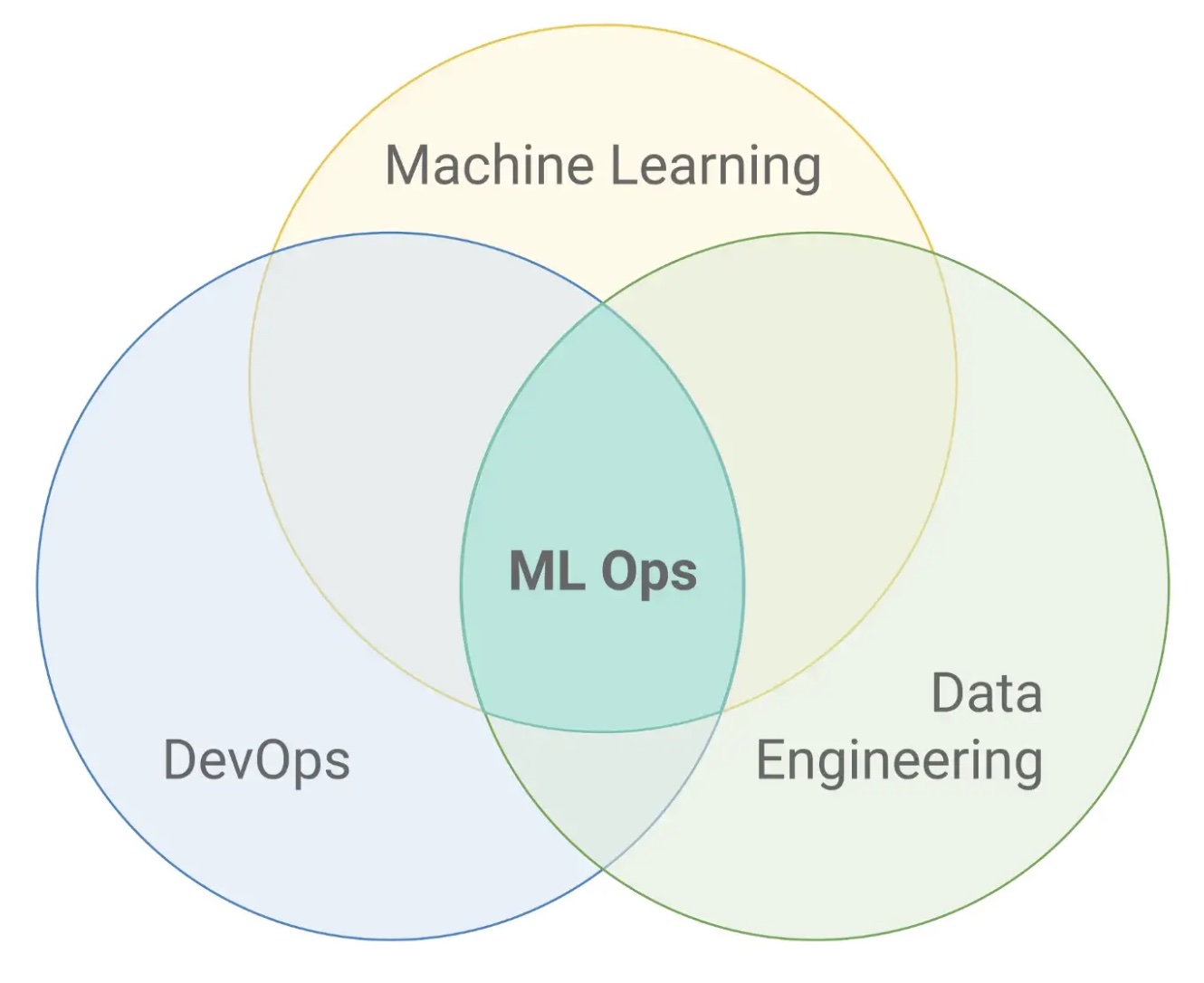
フローを簡単に表すと以下のようになり, これの自動化や合理化を行うものである.

調べる中でMLシステム開発におけるMLそれ自体の要素は非常に少ないことがわかった.
やはり, まずはDevOpsが重要であり, データをどう扱うかのデータエンジニアリングも考える必要がある.
このことからMLOpsはML, DevOps, データエンジニアリングの交差であるとしばしば説明される.
MLOps: Machine Learning as an Engineering Discipline
今回紹介したのはあくまでBig Tech3社の考えるMLOpsだということは忘れてはいけない.
特にJTC (Japanese Traditional Company) はシステムや人を含めたリソース, 組織の構造が違うためそのまますぐの適用は難しいと思われる.
日本を含めた他の実例は多くあるためそれらも参考にしたい.
[MLOpsの事例]
-
Netflix : Netflix Presents: A Human Friendly Approach to MLOps — Julie Pitt and Ashish Rastogi, Netflix
-
ヤマト運輸 : ヤマト運輸、MLOpsで経営リソースの最適配置を実現 「お手本がないものを1から作り上げ、機械学習モデルの運用安定と高速化を勝ち取った」
-
Yahoo! Japan : ヤフーのAIプラットフォーム紹介 〜 AI開発をより手軽に
-
NTT docomo : たった3人で運用するドコモを支える機械学習基盤の作り方 ー Kubernates × Airflow × DataRobot を使ったMLOpsパイプライン ー
MLOpsに使われる技術
MLOps実現するためのライブラリやツール, サービスについて調査した.
結論から言うと, その定義同様, これがスタンダードというものはない.
各々がインフラやコスト, 利便性や担当者の習熟度に合わせその時のベストプラクティスを選択している印象がある.
いくつか例を挙げて紹介する.
[AWSのサービス]
先にも紹介したが, AWSのサービスを組み合わせることで必要な機能が実装される.
ML開発にはPyTorchやTensorflowなど既存のフレームワークを採用できる.
AWSで構築するMLOps基盤

[Microsoft Azureのサービス]
AzureもAWS同様にサービスを組み合わせることで必要な機能が実装される.
Azure Machine LearningによるMLOpsとそのポイント

[Google Cloudのサービス]
Google Cloud AI Platform PipelinesというMLOpsのプラットフォームを提供している.
長らくベータ版が続いているようだ.
Creating a machine learning pipeline
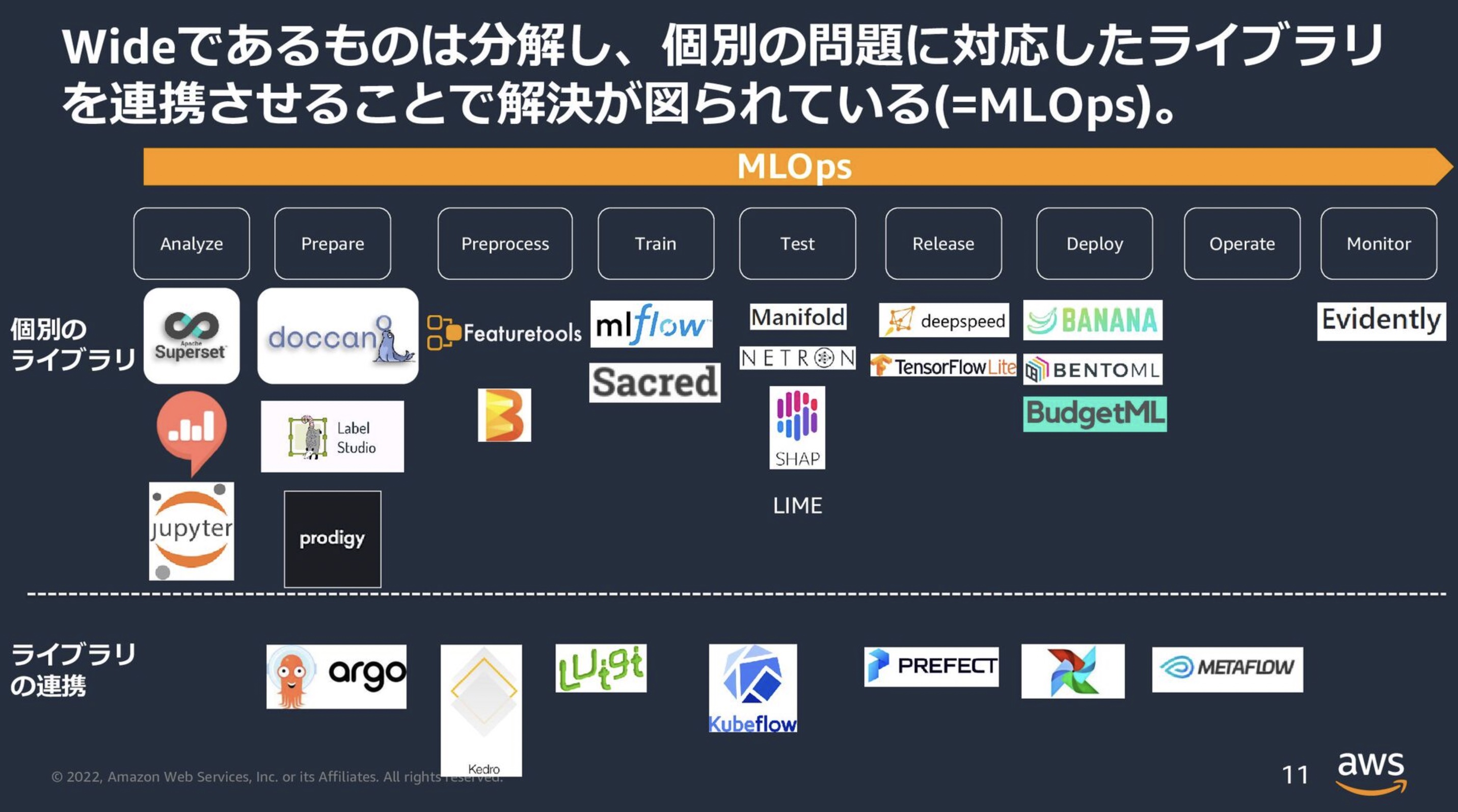
[個別ライブラリの組み合わせ]
MLOpsの各フローの対応したライブラリを組み合わせることで必要な機能を実装する.
色々と実例を漁ったが, 以下がよく採用されているように思える.
ユースケースや扱うデータで変わるため, あくまで一例である.
- 準備
- Apache Spark
- SQL
- Jupyter
- Mongo DB
- 開発
- Pytorch
- Tensolflow
- MLflow
- Apache Spark
- Onnx
- 運用
- Docker
- Apache Spark
- databricks
例:
MLOpsのこれまでとこれから
MLflow: Infrastructure for a Complete Machine Learning Life Cycle

もちろん, 実際には個別ライブラリや各クラウドサービスを組み合わせたり, 開発フェーズで変更したりなど多様なやり方が見られる.
MLOps全体を見る場合にはあまりに多くのスキルセットが要求されそうだ…
(実装編) を進める中で良いプラクティスを探していきたい.
まとめ
今回のパート (勉強編) ではBig Techなどの説明からMLOpsが何であるかを調べた.
MLOpsというのはDevOpsの延長であり, データエンジニアリングの要素も含む.
一般のソフトウェア開発にはないML開発に特有の複雑な開発サイクルを自動化・合理化することを目指している.
データの準備や管理, モデルの開発, 運用といったフローの中で, それぞれ適当なツールやシステムをユースケースや環境に合わせて選択する必要がある.
また, それに関わる人のロールは細かく定義されるが, 実際には明確な線引きが難しいケースがある.
各ロール間のコミュニケーションも大切な要素である.
最後に私の感想になるが, MLOpsはまだ発展途上であることが面白いと思う.
機械学習分野の発展は目まぐるしいものがあり, それを製品へ活かすことで新たな価値を創出する動きが加速している.
こうした流れに対する試行錯誤の様子が多くの説明・実例からも見てとれる.
現時点では定義もプラクティスも明確な正解はなく, 各社各人が手探りで進んでいるようだ.
MLOpsを実践するにあたり, ロールを選べば良いため全てを演じる必要はないのだが, 一通り経験してみたい.
実はApache Spark等を使い簡易なMLシステムを構築していたのがカレンダー登録に間に合わなかった…
次回「MLOpsに触れてみる (実装編) 」は少し時間をおいて何かしから有用なユースケースで開発をしてみるつもりだ.
一緒にやってくれる方いればぜひ.
ではまた.
参考
Hidden Technical Debt in Machine Learning Systems
MLOps: Model management, deployment, and monitoring with Azure Machine Learning
MLOps: Continuous delivery and automation pipelines in machine learning
MLOps foundation roadmap for enterprises with Amazon SageMaker
MLOps: Machine Learning as an Engineering Discipline
Azure Machine LearningによるMLOpsとそのポイント
Creating a machine learning pipeline
MLflow: Infrastructure for a Complete Machine Learning Life Cycle